Self-evolution is a core module of the Agent Harness. With it, an Agent can keep improving across long-running tasks: refining its own skills, recording user feedback and preferences, and reviewing its own work to keep getting better. This post uses the open-source project CowAgent as a worked example to walk through the architecture and engineering behind a five-layer self-evolution mechanism.
Overall Design
Self-evolution is not just about making an Agent remember things. It is about letting the Agent improve and repair itself through continuous feedback. The mechanism divides into five layers by depth: recording information, retaining information, taking action, consolidating, and self-rewriting. Each depth differs in what it improves, when it triggers, and how far its effects reach.
Two questions drive the implementation: when evolution is triggered and what gets improved. In CowAgent, the full mechanism is built from five layers, each mapping to a different depth of evolution: basic memory and knowledge maintenance, smart context summarization, post-session review, dream-based memory consolidation, and source-code self-update. The overall architecture:

| Layer | What it improves | When it triggers | Depth |
|---|---|---|---|
| Basic memory & knowledge maintenance | Memory / knowledge / prompts | During each conversation | Record |
| Smart context summarization | Memory | When context overflows | Retain |
| Post-session review | Skills / memory / prompts / tasks | After a session goes idle | Act |
| Dream-based memory consolidation | Long-term memory | Daily, on schedule | Consolidate |
| Source-code self-update | Code | Passive / active trigger | Self-rewrite |
1. Basic Memory and Knowledge Maintenance
The most basic layer of self-evolution happens inside every conversation. Guided by the model's tool-use decisions and the system prompt, the Agent judges whether a conversation contains anything worth keeping, then uses built-in tools to write preferences, decisions, facts, and lessons into long-term memory, reusable knowledge into the knowledge base, and anything about its own persona or operating rules into prompt files.
These three kinds of information differ in target and timing:
- Memory: persisted as files in the workspace, split into core memory and daily memory. Core memory (
MEMORY.md) holds long-lived facts such as user preferences and key decisions, and is injected into the system prompt of every conversation, so it must stay concise. Daily memory (memory/YYYY-MM-DD.md) records key events and conversation summaries by day, and is loaded only when the Agent uses its memory-retrieval tool. - Knowledge base: stored as Markdown source files in the workspace with vectorized data in the database, organized by topic and cross-linked into a knowledge graph. When a conversation involves research or learning, the Agent proactively files the organized knowledge here.
- Prompts: persona (
AGENT.md), rules (RULE.md), and user info (USER.md) can also be edited mid-conversation. All of them load into the system prompt, letting the Agent adjust its own settings based on feedback and fit the user's habits.

Example above: in a single message the user states a preference and asks the Agent to research a new concept. While answering, the Agent writes the preference into memory and files the organized material into the knowledge base.
2. Smart Context Summarization
The previous layer is about how to remember key information. This one is about how the Agent avoids losing information as it evolves. Context is short-term memory, with configurable limits on both turn count and token length. When those limits are exceeded, the system does not simply drop old messages. It distills and summarizes the important parts and writes them into daily memory. The compression runs in four steps:
- Truncate oversized tool results: the first and cheapest step. When a single tool result in a past turn (say, a search that returned tens of thousands of lines) exceeds a threshold, only the head and tail are kept along with a short elision note; the current in-progress turn is left untouched. This step is pure string handling with no model call, and it often absorbs most of the growth.
- Trim by complete turns: when the turn limit is exceeded, the system trims the oldest half using a full conversation turn as the smallest unit, rather than deleting messages one by one. This keeps each tool call's input and result paired, so the model is never left with a tool call that has no matching result. The trimmed content is not discarded: an LLM organizes, distills, and summarizes it, then writes it into the day's daily memory for persistence and injects the summary back at the start of the retained messages, so the model can still pick up the thread after the raw detail is gone.
- Compress by token budget: if the token limit is still exceeded after trimming turns, a finer pass runs. When there are only a few turns, each turn is compressed to text (keeping the user's first question and the Agent's final reply, stripping the tool-call chain in between); when there are many turns, the earlier half is trimmed and summarized.
- Overflow fallback: if the model API itself throws a context-overflow error, the system first summarizes the current conversation into memory, then applies a more aggressive truncation. This is the last line of defense.

3. Post-Session Review
Post-session review is the most active and most central part of self-evolution. When a session wraps up and goes idle, the Agent revisits the whole conversation: fixing problems that surfaced, turning reusable workflows into skills, finishing tasks that were left undone.
3.1 What It Improves
Here is what a review mainly does:
- Improve and create skills: when a Skill exposed a problem in use (wrong configuration, a missing step, stale content), the Agent edits the skill file directly so it does not recur; when a reusable workflow emerged in the conversation, the Agent turns it into a new skill so the next similar task runs more reliably. This step turns the Agent from a user of skills into a maintainer of skills.
- Finish unfinished tasks: tasks promised to the user but left undone, or interrupted by a transient failure (a network hiccup, an environment issue), get reviewed and attempted again.
- Fill gaps in memory / knowledge / prompts: only as a backstop. The main conversation already writes memory and knowledge on its own, so this is a fallback.

Example above: during a post-session review the Agent spots a reusable workflow, turns it into a new skill, and notifies the user.
Two design trade-offs run through this layer:
- Skills and unfinished tasks are the primary value; memory, knowledge, and prompts are only gap-filling, since they are already covered by the other layers and need no duplicate attention.
- Fix the source, do not just log the symptom. If the root cause lives in a skill, the right move is to edit that skill, not to leave a note in memory saying "skill X has a bug." Many Agent projects stop at the symptom. Recording a symptom does not prevent recurrence; only fixing the source does.
3.2 When It Triggers
Review fires after a session ends and stays idle for a while, and only once enough conversation has accumulated to be worth reviewing. In short: the user has stopped chatting, and the session held enough substance. Both conditions must hold before a single review runs.
In the project, self-evolution can be toggled on or off from the Web console, and the idle threshold (10 minutes by default) and turn threshold (6 turns by default) can be tuned further in the config file.

3.3 Safety and Control
Once you let an Agent edit itself, the question that matters most is whether it might break something or interrupt the user. A system that can modify itself tends to fail in a few specific ways: writing wrong information into memory or skills; overstepping its scope and touching built-in modules while running commands; or making changes that cannot be traced or rolled back.
So this layer is designed around three goals: traceable, reversible, isolated execution.
- Isolated execution: each review is a separate, asynchronous, temporary task. It uses the same main model but with a sharply narrowed tool set (it can only read context and edit memory and skills), so it neither pollutes nor slows the main conversation. The project's own built-in skills are write-protected at the code level.
- Reversible changes: relevant files are backed up automatically before the Agent edits them. If a user disagrees with a change, sending a message like "undo the last change" restores the workspace.
- Traceable changes: every change is persisted in the workspace, and the details can be tracked under "Web console → Memory → Self-Evolution."
- No change, no interruption: after a review, the Agent checks whether anything was actually changed. If so, it pushes the result to the user; if not, it stays silent and the user notices nothing.

4. Dream-Based Memory Consolidation
Dream-based memory consolidation (Deep Dream) runs as a nightly scheduled task (23:55 by default). It first writes each session's context (short-term memory) for the day into daily memory, then runs a distillation pass: it reads the current core memory and the day's daily memory and asks the model to deduplicate, merge near-duplicate entries, prune, extract new information, and replace stale entries, producing a refined core memory. It also writes a narrative dream journal recording what this pass found, merged, and cleaned up.
This is a daily, global-scope form of self-evolution, a single sweep over all of the day's sessions. It addresses the two problems long-term memory runs into over time: unbounded growth and internal contradiction. The pass follows a few core rules:
- Multiple near-identical entries are merged into one higher-density statement.
- New information worth keeping (preferences, decisions, rules, lessons) is extracted from the daily journals; when new and old memory conflict, the new entry replaces the old one.
- Temporary records, empty entries, and redundancy already covered elsewhere are cleaned out, keeping core memory (
MEMORY.md) within a bounded size (around 50 entries).

A few safeguards keep consolidation safe and controlled:
- If there are no new journals for the day, the pass is skipped, so it never overwrites existing core memory with nothing.
- Journal content and each message are hashed for deduplication, so the same content is never written into daily memory twice (even across days).
- The prompt strongly constrains the pass to the actual records, so it does not invent memories that never existed.
Besides the nightly run, consolidation can be triggered manually for the last N days. All consolidation output is persisted in the workspace as journals.
5. Source-Code Self-Update
Source-code self-update means the Agent modifies its own code at runtime and restarts, to solve problems that external skills and tools cannot. Because this carries some risk, the discussion here is more open-ended.
For safety, CowAgent does not ship source-code self-update as a built-in, enabled feature. Users can still achieve it by asking for it directly. The project installs from source by default, so the Agent already has access to its own code; you only need to tell it where the project code lives and give a clear change request, and it can modify its own code and restart. To make it more proactive about editing code, you can wrap this into a Skill or prompt as a built-in capability.
Editing code changes the Agent's capabilities themselves, not just data like memory or skills, so the blast radius is larger. Two hard problems stand out:
- How to keep the Agent from breaking the code and failing to start.
- How to shut down the current process and start a new one from within the running process.
To handle both, the project provides a cow self-restart CLI command dedicated to the Agent restarting itself. It first runs a self-check on the code; any import or interpreter error aborts the restart. Once the check passes, it launches a relay process detached from the current process tree, which shuts down the old process and starts a new one, achieving a graceful self-restart.
In an open-source setting there is one more issue: version conflicts. Once the code is modified locally, it diverges from the upstream branch, and a later official update may conflict on pull. Resolving that still relies on a person, or on the Agent's help.
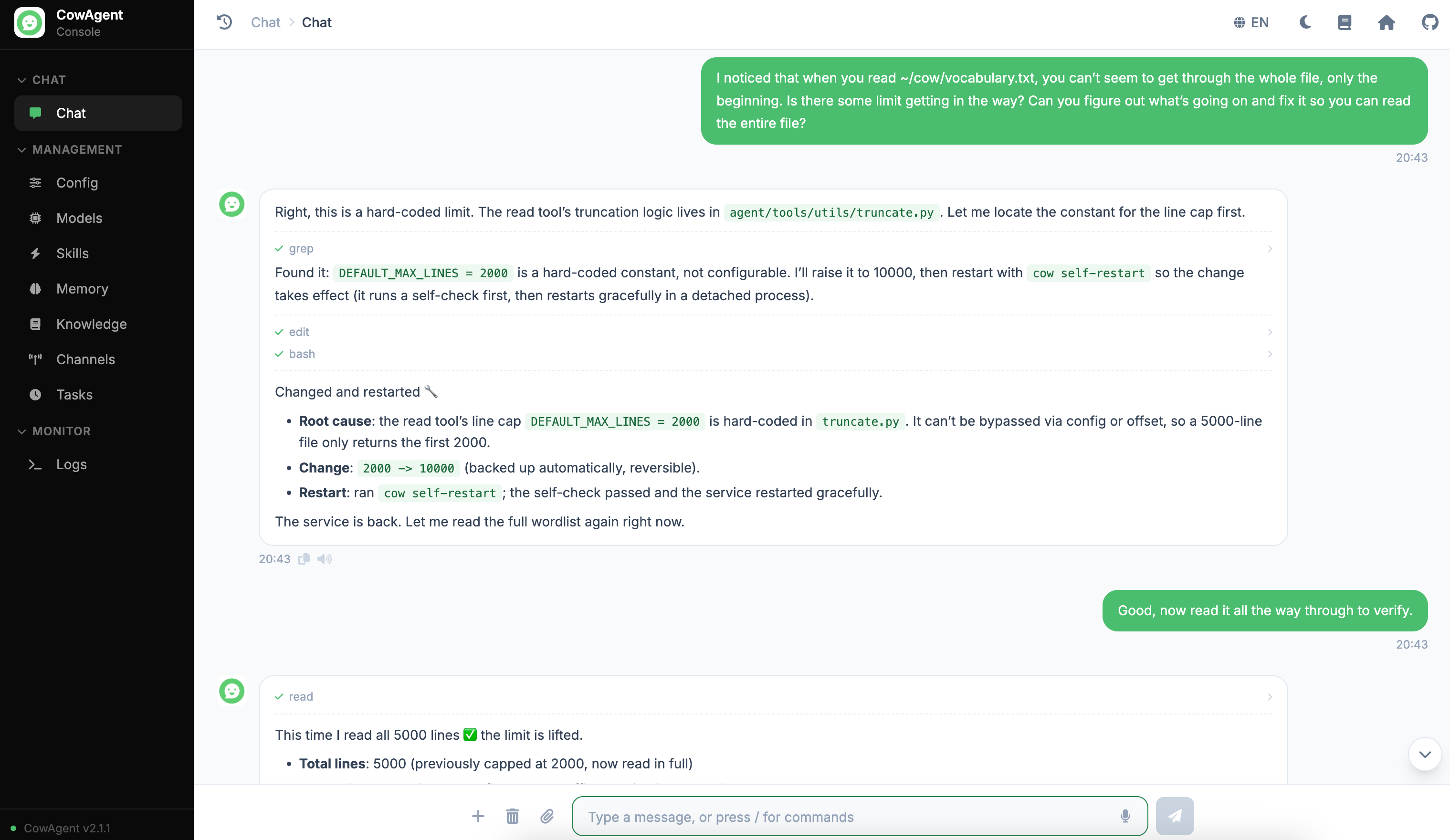
Example above: the Agent locates a problem in its own code and fixes it, then runs the command to self-check and restart.
Closing
Across these five layers, the Agent learns to adjust its own prompts, memory, knowledge, skills, and even its source code. Looking back at the design, the hard part was never giving it the ability to change itself; it was making those changes restrained and controllable. The goal is plain: an Agent that understands you better and makes fewer mistakes the more you use it, instead of one that meets you fresh every day.
The implementation here comes from the open-source project CowAgent. If the ideas are useful, the source and docs are there to look at.